Snort 3.0 Beta 3 Released

It's been quite a while since the last Snort 3.0 beta and yesterday we released Beta 3. The reason that it's taken so long to get out the door is that we decided to start doing performance analysis of the Snort 2.8.x analytic engine that was ported over to run on top of SnortSP and the results were... interesting.
When I started developing and designing the Snort 3.0 architecture one of the assumptions that I based my design around was that multi-core computing environments were going to be the norm rather than the exception in the platforms we'd target moving forward. With that in mind and knowing the typical packet analysis load we place on machines with Sourcefire's applications I was looking to utilize CPU cycles more efficiently by performing common processing that happened for every packet (acquire/decode/flow/stream/etc) once and then spreading the analysis (Snort/RNA/etc) across the cores in separate threads. This would allow us to perform parallel processing across analytic engines while only having to perform the common processing tasks they all have to do once.
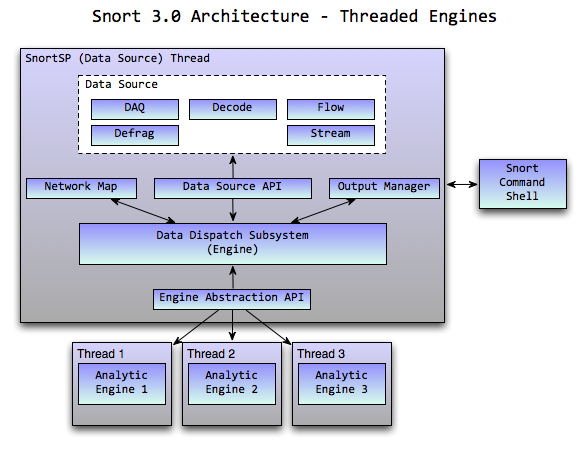
This is great in theory and seemed like we'd see some real performance gains but when we started looking at the Snort 2.8.3.x analytic engine that we put out in the original Beta release we saw that performance was not where we wanted it to be relative to the monolithic Snort 2.8.3.x architecture. Initially we thought that the performance discrepancies were due to inefficiencies that were a byproduct of porting the monolithic Snort 2 packet processing engine to run in a threaded environment due to the incorporation of things like thread-local storage (TLS). Lots and lots of analysis was done over several months, tons of optimizations were made by Russ Combs and Ron Dempster, Snort's run-time processing cycle was studied at length and at the end of the day the performance still wasn't where we wanted it.
Eventually we arrived at the conclusion that the performance issues we were seeing were stemming from the way that modern Intel CPUs use and synchronize cache memory. If you'd like to see some more in-depth discussion on the Intel CPU caching architecture you should take a look at Gustavo's site and check out the articles on caching. The performance hangup we ran into really manifested itself as we tried to distribute traffic across cores on multiple physical dies, the overhead incurred by the data transfers and cache coherency operations required by the cores was costing us lots of CPU cycles.
What has become apparent from performing our analysis and extensive experimentation is that data spreading across the current generation of multi-core Intel CPUs is not something that works well for real-time applications like IPS. Intel CPUs really seem to favor the more traditional load balancing approach that's been used successfully with the Snort 2.x code base for years where independent processes are locked to separate cores and flows are unique to each respective process.
While we were exploring the performance envelope of the Snort 3 code base we looked at a number of different data distribution architectures to move data from the data source subsystem of SnortSP to the analytic engines (i.e. the Snort 2.8.3 engine module). A model that we've found to work well is what we've come to call the "stacks model". The stacks model works a lot like the Snort 2.x preprocessor subsystem but on a somewhat larger scale. Instead of running several analytic engines in separate threads with each thread locked to a CPU, the stacked model runs the engines in the one thread and calls them sequentially, passing the packet stream from engine to engine. The stacks model is included in Beta 3 and is a compile-time option for running the system.

One model that we haven't benchmarked extensively is what I'll call a "single core multithreaded model" where we run one thread per analytic engine but lock them all to the same CPU core, eliminating the cache coherency and sync overhead while paying the price of heavier loading on the individual CPU cores. This will be an area of further research down the road.
We are planning on standing up a public CVS server in the near future to host the Snort 3 code so that we can foster better interaction with the open source community.
The next big hurdles to get over with Snort 3 are development of the TCP stream management subsystem and the Snort 3.0 analytic engine module. Stay tuned for more (and more regular) releases as we get rolling on these subsystems.
Labels: IDS, IPS, Snort, Sourcefire
posted by Martin Roesch @ 4:24 PM
3 comments
![]()

3 Comments:
Did you guys try the Intel Threading Building Blocks library (C++) ? It is probably difficult to get it to work with a C code base, but they do seem have some facilities to address the cache issues.
We worked directly with Intel and they verified what we were seeing, the threading lib wasn't going to solve the data spreading problem. Syncing cache across the FSB at 500,000 packets per second just doesn't work well.
What I really need is a MISD computer...
As a suggestion, may be the architecture figures can be reversed. Basically data source should be at the bottom and analytics at top.
From the figures, it looks like analytics run independent of each other (no direct data dependency). If you allow multiple copies of packets (one for each analytics), overall performance may be better Making packet copy will have performance impact but this may allow you to leverage all cores to the full speed.
Another solution may be to make all data accessed through Engine API strictly read only. Cache coherency issue can be avoided if there are one writer and multiple readers.
Post a Comment
<< Home